


The Evolution of CXL

I visited an ichthyosaur exhibit with my mother recently. Ichthyosaurs were aquatic reptiles that called Nevada their home about 250 million years ago. Well, other places, as well. But there were quite a few in the inland sea that sat in the Great Basin at that time. These creatures grew as large as 60 feet (20 meters). To date, more than a couple hundred have been found in Nevada.
In north-central Nevada, there is Berlin Ichthyosaur State Park. A handful of complete, fossilized skeletons have been excavated, and more are still partially uncovered as the main feature of the park. The Nevada Museum of Art had a rotating exhibit based on ichthyosaurs recently, and I went there with my mother when she came to visit.

A long-time anatomy professor, she pointed out the loops on either side of the tailbone, commenting that’s where tendons would have run to allow the tail to articulate. How do we know this? There certainly aren’t Triassic-era tendons around to show us. All that’s left are skeletal remains that failed to escape the gaze of Medusa. But we’re able to see the similarities to existing species and understand the way they worked.
Transporting to a different era
I’m known as (among other things) a storage technology person, a self-titled Storage Janitor. While I’m reasonably versed in the technology of storing data and the types of methods of accessing and protecting it, the primary focus of much of my professional life has been storage transport. That is, the technology of moving bits between storage devices or systems and the compute devices that use them.
To explain this in a little more detail, the original SCSI specification provided a set of commands to read and write data, as well as commands for identifying devices and the like. It also specified how data was transmitted across a parallel bus. That bus expanded from 8 bits to 16 bits, but the signalling and communications across that bus didn’t change much over the first 15 years of life.
Then in the mid-90s, some efforts got underway to increase the bandwidth and the length of these buses. There were probably other efforts, but Fibre Channel was the most significant undertaking with the most industry backing. Fibre Channel needed to figure out how to do the data communication and signalling that had been done with parallel SCSI. But it did not have to change the commands to fetch and put the bits, from the perspective of the CPU. Thus, SCSI got split into command specifications and transport specifications. A way to think of it is the command protocol deals with data at rest, the transport takes care of data in motion.

I got started with storage on Sun Microsystem’s first Fibre Channel product, codenamed Pluto. My job was to code the host bus adapter. I got this job because the storage team didn’t consider Fibre Channel a “real” storage protocol. At the time, I had been working on RS232 drivers for Sun’s workstations and servers. Because Fibre Channel is a serial protocol, the storage team decided to turn it over to the “serial port” guy. And I became a storage transport guy.

Later on, when Fibre Channel completely fumbled its networking aspirations, I moved on to iSCSI, another SCSI storage transport.
Enfabrica Introduces Advanced Compute Fabric SuperNIC
I participated in AI Field Day #5 as a delegate. One of the more fascinating talks was presented by Sankar Rochan, founder of Enfabrica. He started with a discussion of some of the problems AI models and high performance computing face in general. A primary issue is the inability to feed and fetch data to and from compute resources at the rate they’re processed, GPUs in particular,
Like all graphs, the compute resources and available memory bandwidth go up and to the right.

But compute growth is outrunning IO resources, and you can see the lines are continuing to diverge as time goes on.
This leads to another problem that I found even more interesting. AI models are using about 15% less GPU than they are theoretically capable of using, largely due to data starvation at the GPUs. The models are capable of using about 60% of the available GPU floating point operations (FLOPs), but are only using in the neighborhood of 30-50%. Feeding the beast is overwhelming its access to memory. (It’s also worth noting the models are incapable of saturating the available GPUs. Designing efficient software is a problem I’m helping address with the team at Magnition.)

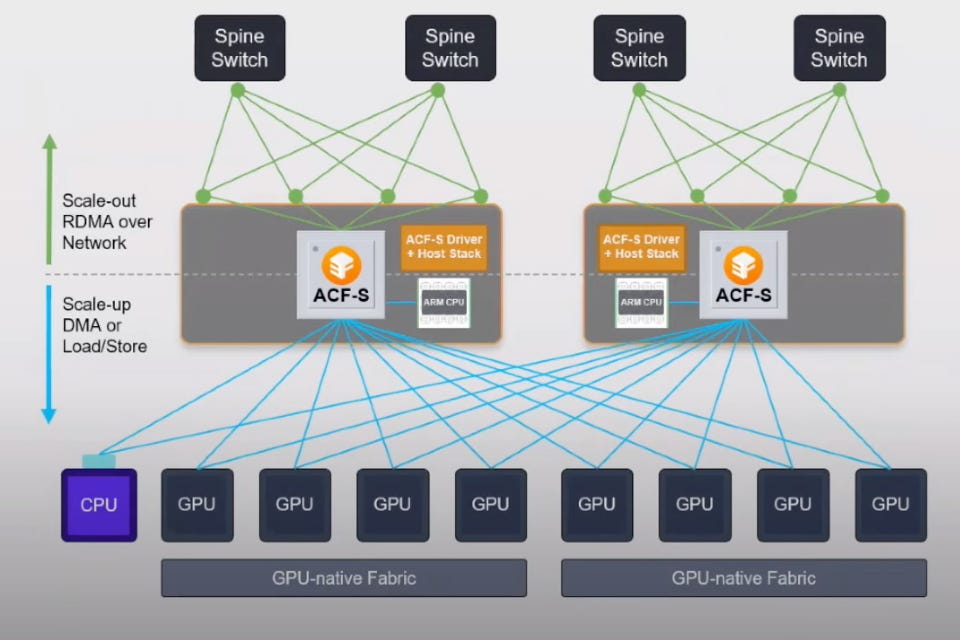
Enfabrica is tackling this with what they’re naming the Accelerated Compute Fabric SuperNIC. The SuperNIC is a memory and Ethernet crossbar switch, providing up to 128 lanes of 64-Gbit PCIe and 8 ports of 400-Gbit Ethernet. (Or 4 ports of 800-Gbt, if you’re so inclined.) That gives this little monster 3.2Tbits of network bandwidth and about 5Tbits of memory bandwidth.
The fact that you can switch between any of the PCIe lanes and Ethernet ports means this becomes a multi-purpose memory and network switch.

The goal of this design is to be able to build a large-scale network of GPUs that share resources and are able to access remote memory via Ethernet as if it were local, preventing stalling and bottlenecks in GPU workloads. It does this without having to change any programming models, meaning no existing applications need to change.
The SuperNIC is capable of offloading some of the memory mapping by implementing portions of an IO memory management unit (IOMMU). This prevents repeated access to the host CPU to keep track of memory maps.
The SuperNIC uses CXL to access the GPU memory and essentially acts like a CXL switch in this case. I wrote about CXL previously as an emerging technology. The fact that the SuperNIC has programmable firmware means that future advancement in the CXL standard won’t necessitate a spin of the hardware to work properly.
I also noticed that since AI Field Day #5, Enfabrica has joined the Ultra Ethernet Consortium. Sankar commented that the programmability would allow them to comply with those standards, as well.
This brief description doesn’t do justice to what might be game changing technology, probably coming to a motherboard near you sometime soon. For more info, you can watch the AI Field Day #5 videos and check out their website
The more things change …
Once Fibre Channel laid the groundwork for separating command and transport aspects of storage and memory protocols, others were inevitable to follow. No systems use parallel SCSI interfaces anymore. High-end servers and storage arrays sometimes use serial-attached SCSI (SAS), and lower-end systems use SATA, essentially a less-feature-laden variant of SAS.
More recently, SCSI got a reboot with NVMe (originally “Non-Volatile Memory Express,” but now used largely as an SSD interconnect). It had been around only a few years when tech companies started prying it away from its PCIe-transport underpinnings. I spent some time working with Fungible (now defunct) working on their NVMe-over-TCP implementation. Others have used other Ethernet protocols to transport NVMe.
As surely as anatomy tells us that ichthyosaurs had and as current reptiles have tendons on either side of their tails, I figured it was only a matter of time before CXL found its way onto some other transport. CXL was emerging technology when I wrote about it in 2023. Now, 18 months later, Enfabrica has produced what amounts to a CXL-over-Ethernet engine. Evolution hangs onto the concepts that work, even if those things around them change.
Do check out what Enfabrica has going on. And I’ll be at AI Field Day #6 next week, January 29th and 30th. Tune in live and ask me and the other delegates questions for the vendors, VMware and Memverge.